В предыдущих статьях учебника по Selenium Python мы рассмотрели «Исключения в Selenium Python». В этом руководстве мы изучим, как обрабатывать веб-таблицы в Selenium Python.
Веб-таблица в документе HTML определяется тегом <table>. Строки таблицы представлены тегом <tr>, а столбцы таблицы представлены тегом <td>. В основном каждая таблица имеет заголовки, представленные тегом <th>.
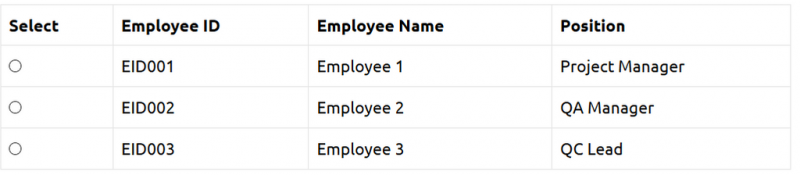
Давайте рассмотрим приведенную ниже таблицу для нашего обсуждения.
Проверьте эту ссылку для просмотра приведенной ниже таблицы.

< р>Чтобы работать с веб-таблицей, мы должны иметь возможность обрабатывать такие сценарии, как получение номеров строк, номеров столбцов, конкретного значения ячейки, выборки всех значений ячеек в строке, выборки всех значений ячеек в столбце, выборки всех ячеек. значения и т. д.
Чтобы вычислить общее количество строк, мы сначала создадим настраиваемый xpath для представления всех строк в таблице с помощью метода find_elements_by_xpath(). Поскольку этот метод возвращает список, мы можем получить количество строк с помощью len.
Реализация кода для подсчета количества строк в таблице.
| 12345678910111213 | # импортировать веб-драйвер из selenium import webdriver# импортировать класс Keys из selenium.webdriver.common import keysdriver = webdriver.Chrome (executable_path=”C:\chromedriver.exe”)# получить метод для запуска URLdriver.get(“https://www.softwaretestingmaterial.com/sample-webpage- to-automate/”)# для идентификации таблицы rowsl = driver.find_elements_by_xpath (“//*[@class= 'spTable']/tbody/tr”)# для получения количество строк len methodprint (len(l))# для закрытия браузера.quit () |
Чтобы вычислить общее количество столбцов, мы сначала создадим настроенный XPath для представления всех строк в таблице с помощью метода find_elements_by_xpath(). Поскольку этот метод возвращает список, мы можем получить количество строк с помощью метода len. Мы должны исправить номер строки перед вычислением количества столбцов с помощью <td>. Если мы устанавливаем строку 1, мы должны использовать <th> для столбцов. Для любой другой строки, кроме 1, мы должны использовать <td>.
Реализация кода для подсчета количества столбцов в таблице.
| 12345678910111213 | # импортировать веб-драйвер из selenium import webdriver# импортировать класс Keys из selenium.webdriver.common import keysdriver = webdriver.Chrome (executable_path=”C:\chromedriver.exe”)# получить метод для запуска URLdriver.get(“https://www.softwaretestingmaterial.com/sample-webpage- to-automate/”)# для идентификации столбцов в строке 3l=driver.find_elements_by_xpath(“//*[@class= 'spTable']/tbody/tr[3]/td”)# для получения количества столбцов len methodprint (len(l))# для закрытия browserdriver.quit () |
Чтобы получить заголовки в таблице, мы сначала создадим настроенный XPath для представления все строки в таблице с помощью find_elements_by_xpath()метод. Поскольку этот метод возвращает список, мы можем получить количество строк с помощью метода len. Нам нужно перебрать строку номер 1, а затем перейти к <th>. Как только мы получим первую строку, мы воспользуемся методом text, чтобы получить все заголовки таблицы.
Реализация кода для получения заголовков таблицы. webkit-размер вкладки: 4; размер вкладки: 4; размер шрифта: 12 пикселей! важно; высота строки: 15 пикселей! важно># импортировать веб-драйвер из selenium import webdriver # импортировать класс Keys из selenium.webdriver.common import keys driver = webdriver.Chrome (executable_path="C:\chromedriver.exe") # получить метод для запуска URL driver.get("https://www.softwaretestingmaterial.com/sample-webpage-to-automate/") # для определения заголовков столбцов таблицы в строке 1 l=driver.find_elements_by_xpath (&# 34;//*[@class= 'spTable']/tbody/tr[1]/th") # пройтись по списку заголовков для i in l : # получить заголовок с помощью текстовый метод print (i.text) #для закрытия браузера driver.close ()
| 123456789101112131415 | # импортировать веб-драйвер из selenium import webdriver# импортировать класс Keys из selenium.webdriver.common import keysdriver = webdriver.Chrome (executable_path=”C:\chromedriver.exe”)# получить метод для запуска URLdriver.get(“https://www.softwaretestingmaterial.com/sample-webpage- to-automate/”)# для идентификации заголовков столбцов таблицы в строке 1l=driver.find_elements_by_xpath (“//*[@class= 'spTable']/tbody/tr[1 ]/th”)# для обхода списка заголовков для i в l :# для получения заголовка с текстом methodprint (i.text)#для закрытия браузераdriver.close () |
Чтобы получить все значения ячеек определенной строки, мы сначала создадим настроенный XPath для представления всех данных ячеек строки в таблице с помощью метода find_elements_by_xpath(). Поскольку этот метод возвращает список, мы можем получить количество строк с помощью метода len. Мы должны перебирать столбцы с определенным номером строки [больше 1], имея тег <td>. Как только мы получим все значения в этой конкретной строке, мы будем использовать метод text для получения всех данных ячейки.
Реализация кода для получения данных ячейки определенной строки.
| 123456789101112131415 | # импортировать веб-драйвер из selenium import webdriver# импортировать класс Keys из selenium.webdriver.common import keysdriver = webdriver.Chrome (executable_path=”C:\chromedriver.exe”)# получить метод для запуска URLdriver.get(“https://www.softwaretestingmaterial.com/sample-webpage- to-automate/”)# для идентификации таблицы columnl=driver.find_elements_by_xpath (“//*[@class= 'spTable']/tbody/tr[3]/td” )# пройтись по списку данных ячейки строки 3for i in l :# получить данные ячейки текстовым методомprint (i.text)#закрыть браузерdriver.close () |
Чтобы получить все значения ячеек определенного столбца, мы сначала создадим настроенный XPath для представления всех данных ячеек столбца в таблице с помощью метода find_elements_by_xpath(). Поскольку этот метод возвращает список, мы можем получить количество строк с помощью метода len. Мы должны перебирать строки столбца с определенным номером, используя тег <tr>. Как только мы получим все значения в этом конкретном столбце, мы будем использовать текстдля получения всех данных ячеек.
Реализация кода для получения данных ячеек определенного столбца.
| 123456789101112131415 | # импортировать веб-драйвер из selenium import webdriver# импортировать класс Keys из selenium.webdriver.common import keysdriver = webdriver.Chrome (executable_path=”C:\chromedriver.exe”)# получить метод для запуска URLdriver.get(“https://www.softwaretestingmaterial.com/sample-webpage- to-automate/”)# для идентификации таблицы columnl=driver.find_elements_by_xpath (“//*[@class= 'spTable']/tbody/tr/td[3]” )# пройтись по списку данных ячейки столбца 3for i in l :# получить данные ячейки текстовым методомprint (i.text)#закрыть браузерdriver.close () |
Чтобы получить все значения ячеек таблицы, мы сначала создадим настроенный XPath для представления всех строк и столбцов в таблице с помощью метода find_elements_by_xpath(). Поскольку этот метод возвращает список, мы можем получить количество строк и столбцов с помощью len.метод. Нам нужно выполнить итерацию по каждой строке и каждому столбцу конкретной таблицы, а затем получить данные ячейки с помощью метода text.
Реализация кода для получения всех данных ячейки в таблице.
| 12345678910111213141516171819202122232425 | # импортировать веб-драйвер из selenium import webdriver# импортировать класс Keys из selenium.webdriver.common import keysdriver = webdriver.Chrome (executable_path=”C:\chromedriver.exe”)# получить метод для запуска URLu=”https://www .softwaretestingmaterial.com/sample-webpage-to-automate/”driver. get (u)# для идентификации строк таблицы r = driver.find_elements_by_xpath (“//table[@class= 'spTable']/tbody/tr”)# для идентификации столбцов таблицыc = driver.find_elements_by_xpath (“//*[@class = 'spTable']/tbody/tr[3]/td”)# для получения количества строк с помощью len methodrc = len (r)# для получения количества столбцов с помощью len methodcc = len (c)# для обхода строк таблицы, исключая headersfor i в диапазоне (2, rc + 1): # для обхода столбца таблицы для j в диапазоне (1, cc + 1) :# для получения всех данных ячейки с текстом methodd = driver.find_element_by_xpath (“//tr[ “+str(i)+”]/td[“+str(j)+”]”).textprint (d)#для закрытия браузераdriver.close () |
Чтобы проверить, существует ли определенный текст в таблице, мы сначала создадим настроенный xpath для представления всех строк и столбцов в таблице с помощью метода find_elements_by_xpath(). Поскольку этот метод возвращает список, мы можем получить количество строк и столбцов с помощью метода len.
Мы должны перебрать каждую строку и каждый столбец конкретной таблицы, а затем выбрать ячейку. данные методом text. Как только данные ячейки будут получены, мы проверим, совпадают ли они с текстом, который мы ищем, с помощью text ()функция в xpath.
Реализация кода для поиска определенного текста в таблице.
| 12345678910111213141516171819202122232425262728293031 | # импортировать веб-драйвер из selenium import webdriver# импортировать класс Keys из selenium.webdriver.common import keysdriver = webdriver.Chrome (executable_path=”C:\chromedriver.exe”)# получить метод для запуска URLu=”https://www .softwaretestingmaterial.com/sample-webpage-to-automate/”driver. get (u)# для идентификации строк таблицы r = driver.find_elements_by_xpath (“//table[@class= 'spTable']/tbody/tr”)# для идентификации столбцов таблицыc = driver.find_elements_by_xpath (“//*[@class = 'spTable']/tbody/tr[3]/td”)# для получения количества строк с помощью len methodrc = len (r)# для получения количества столбцов с помощью len methodcc = len (c)# для обхода строк таблицы, исключая headersfor i в диапазоне (2, rc + 1): # для обхода столбца таблицы для j в диапазоне (1, cc + 1) :# для получения всех данных ячейки с текстом methodd = driver.find_element_by_xpath (“//tr[ “+str(i)+”]/td[“+str(j)+”]”).text# для поиска необходимого textm = driver.find_elements_by_xpath (“//td[text() = 'EID001'] “)# чтобы получить размер списка с помощью методов len = len (m)# проверьте, больше ли размер списка 0If (s > 0) :print (“Текст найден”) # чтобы закрыть браузер, драйвер.close () |
Чтобы получить значение из определенной ячейки в таблице, мы сначала создадим настраиваемый XPath для идентификации ячейки с помощью find_element_by_xpath() метод
Реализация кода для получения значения из конкретной ячейки. 4;-webkit-размер вкладки:4;размер вкладки:4;размер шрифта:12px!важно;высота строки:15px!важно># импортировать веб-драйвер из selenium import webdriver # импортировать класс Keys из selenium.webdriver.common import keys driver = webdriver.Chrome (executable_path="C:\chromedriver.exe") # получить метод для запуска URL-адрес u="https://www.softwaretestingmaterial.com/sample-webpage-to-automate/" Водитель. get (u) # для идентификации ячейки, строки 3 и столбца 2 c = driver.find_element_by_xpath ("//*[@class= 'spTable']/tbody/tr[3]/td [2]") # получить текст print (c.text) #закрыть браузер driver.close()
| 1234567891011121314 | # импортировать веб-драйвер из selenium import webdriver# импортировать класс Keys из selenium.webdriver.common import keysdriver = webdriver.Chrome (executable_path= “C:\chromedriver.exe”)# получить метод для запуска драйвера URLu=”https://www.softwaretestingmaterial.com/sample-webpage-to-automate/”. get (u)# для идентификации ячейки, строки 3 и столбца 2c = driver.find_element_by_xpath (“//*[@class= 'spTable']/tbody/tr[3]/td[2]”)# для получения textprint (c.text)#to close the browserdriver.close() |
В следующей статье мы узнаем Обработка файлов cookie в Selenium Python
TAG: qa
Еще об этом:
 КАК ОБРАЩАТЬСЯ С ВЫПАДАЮЩИМ СПИСКОМ И МНОЖЕСТВЕННЫМ ВЫБОРОМ, ИСПОЛЬЗУЯ SELENIUM WEBDRIVER
КАК ОБРАЩАТЬСЯ С ВЫПАДАЮЩИМ СПИСКОМ И МНОЖЕСТВЕННЫМ ВЫБОРОМ, ИСПОЛЬЗУЯ SELENIUM WEBDRIVER
 СТРУКТУРА, УПРАВЛЯЕМАЯ ДАННЫМИ, В SELENIUM WEBDRIVER | МАТЕРИАЛ ДЛЯ ТЕСТИРОВАНИЯ ПРОГРАММНОГО ОБЕСПЕЧЕНИЯ
СТРУКТУРА, УПРАВЛЯЕМАЯ ДАННЫМИ, В SELENIUM WEBDRIVER | МАТЕРИАЛ ДЛЯ ТЕСТИРОВАНИЯ ПРОГРАММНОГО ОБЕСПЕЧЕНИЯ
 СЕЛЕНИУМ 4 | КАК СДЕЛАТЬ СКРИНШОТ ПОЛНОЙ СТРАНИЦЫ С ИСПОЛЬЗОВАНИЕМ SELENIUM 4
КАК ОБРАЩАТЬСЯ С ДЕТСКИМ ОКНОМ, ФРЕЙМАМИ, ПРЕДУПРЕЖДЕНИЯМИ В SELENIUM PYTHON
СЕЛЕНИУМ 4 | КАК СДЕЛАТЬ СКРИНШОТ ПОЛНОЙ СТРАНИЦЫ С ИСПОЛЬЗОВАНИЕМ SELENIUM 4
КАК ОБРАЩАТЬСЯ С ДЕТСКИМ ОКНОМ, ФРЕЙМАМИ, ПРЕДУПРЕЖДЕНИЯМИ В SELENIUM PYTHON
 ИЗУЧИТЕ РУКОВОДСТВО ПО СЕЛЕКТОРУ CSS В SELENIUM WEBDRIVER [БЕЗ ИСПОЛЬЗОВАНИЯ КАКИХ-ЛИБО ИНСТРУМЕНТОВ]
ИЗУЧИТЕ РУКОВОДСТВО ПО СЕЛЕКТОРУ CSS В SELENIUM WEBDRIVER [БЕЗ ИСПОЛЬЗОВАНИЯ КАКИХ-ЛИБО ИНСТРУМЕНТОВ]
 КАК СОЗДАВАТЬ ОБЪЕМНЫЕ ОТЧЕТЫ В SELENIUM WEBDRIVER [ОБНОВЛЕНИЕ 2022]
КАК СДЕЛАТЬ СКРИНШОТЫ СБОЙНЫХ ТЕСТ-СЛУЧАЕВ С ИСПОЛЬЗОВАНИЕМ SELENIUM WEBDRIVER
КАК СОЗДАВАТЬ ОБЪЕМНЫЕ ОТЧЕТЫ В SELENIUM WEBDRIVER [ОБНОВЛЕНИЕ 2022]
КАК СДЕЛАТЬ СКРИНШОТЫ СБОЙНЫХ ТЕСТ-СЛУЧАЕВ С ИСПОЛЬЗОВАНИЕМ SELENIUM WEBDRIVER
 30+ ПОПУЛЯРНЫХ ВОПРОСОВ О CUCUMBER ДЛЯ ИНТЕРВЬЮ
КАК НАЙТИ КООРДИНАТЫ X Y ВЕБ-ЭЛЕМЕНТОВ, ИСПОЛЬЗУЯ SELENIUM WEBDRIVER
КАК ВЫДЕЛИТЬ ЭЛЕМЕНТ С ИСПОЛЬЗОВАНИЕМ SELENIUM WEBDRIVER
30+ ПОПУЛЯРНЫХ ВОПРОСОВ О CUCUMBER ДЛЯ ИНТЕРВЬЮ
КАК НАЙТИ КООРДИНАТЫ X Y ВЕБ-ЭЛЕМЕНТОВ, ИСПОЛЬЗУЯ SELENIUM WEBDRIVER
КАК ВЫДЕЛИТЬ ЭЛЕМЕНТ С ИСПОЛЬЗОВАНИЕМ SELENIUM WEBDRIVER

