

В В этой статье Учебного пособия по тестированию программного обеспечения мы узнаем, что такое нечеткое тестирование, этапы нечеткого тестирования, как его выполнять и многое другое.
Что такое нечеткое тестирование с примерами?
Нечеткое тестирование — это тип тестирования безопасности, который обнаруживает ошибки кодирования и лазейки в безопасности в программном обеспечении, операционных системах, или сети.
Фазз-тестирование или фаззинг включает в себя ввод огромных объемов случайных данных, называемых фаззом, в тестируемое программное обеспечение, чтобы вызвать его сбой или прорвать его защиту.
Проще говоря, в него вводятся большие объемы неожиданных или случайных входных данных. в системе, что может привести к неожиданным результатам.
Фаззинг часто выявляет уязвимости, которые можно использовать путем внедрения SQL, переполнения буфера, отказа в обслуживании (DOS) и межсайтового сценария. Злоумышленники могут нанести ущерб системе, используя эти уязвимости безопасности.
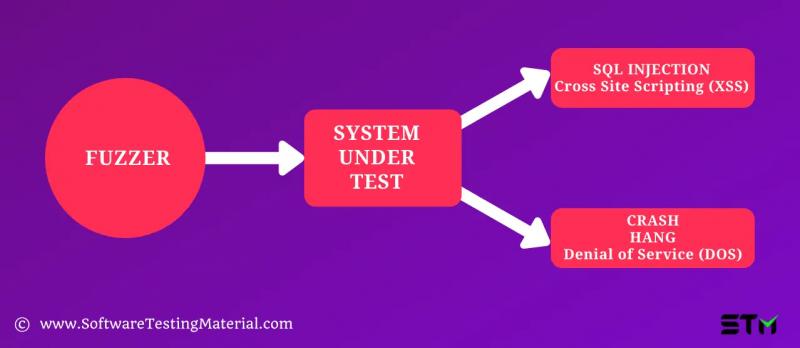
Нечеткое тестирование выполнено использование фаззера — это программа, которая автоматически вводит в программу полуслучайные данные и обнаруживает ошибки.
Фузз-тестирование обычно выполняется автоматически.
Этапы нечеткого тестирования
Целью этого фазз-тестирования является выявление критических ошибок уровня безопасности в программном приложении.

Определить целевую систему
Здесь целевой системой будет разрабатываемое программное обеспечение или его внешняя зависимость. Доступ к целевому компоненту обычно можно получить через несколько интерфейсов и протоколов.
Определить входы
После принятия решения о целевая система, то есть интерфейс, через который вставляются входные данные, мы создали входные данные для таких полей. Для тестирования приложения создаются случайные входные данные.
Создать нечеткие данные
Случайные входные данные, созданные на предыдущем шаге, подвергаются фаззингу, то есть вставляются неожиданные недопустимые значения.
Выполнить тест с использованием нечетких данных
Эти нечеткие данные используются в целях тестирования. Приложение выполняется с использованием нечетких данных в качестве входных значений.
Отслеживание поведения системы
Поведение системы отслеживается на предмет потенциальных уязвимостей безопасности, утечек памяти и сбоев после выполнения тестового примера.
Журнал дефектов
На этом этапе регистрируются дефекты. Эти проблемы решены для повышения качества продукта.
Преимущества нечеткого тестирования
- Нечеткое тестирование защищает приложение от злонамеренных намерений хакеров, выявляя уязвимости безопасности.
- Нечеткое тестирование обычно дополняет другие методы тестирования (например, тестирование черного ящика), с помощью таких сочетаний можно выявить больше ошибок. <ли>При фаззинге системы будет срабатывать неожиданный результат, такие результаты никогда не проектируются разработчиком.
- Фазз-тестирование часто выявляет серьезные дефекты, которые обычно упускаются из виду при разработке программного обеспечения, поэтому оно обеспечивает высокое соотношение выгоды и затрат. .
Почему мы проводим нечеткое тестирование?
- Чтобы обнаружить серьезные ошибки или дефекты безопасности.
- Чтобы защитить приложение от нарушений безопасности.
- Чтобы проверить уязвимость программного обеспечения.
- Чтобы обеспечить максимальный охват приложения.
- Чтобы найти максимальные дефекты с низкими затратами.
- Чтобы обеспечить надежность системы.
- Для обнаружения проблем с памятью. ошибки в приложении.
- Для обнаружения условий гонки и взаимоблокировок в системных потоках.
- Для проверки неопределенного поведения на выходе.
- Для контроля утечек памяти в приложении.
- Для понимания целостности потока управления. – проблемы, связанные с.
Как выполнить нечеткое тестирование
Нечеткое тестирование происходит в интерфейсе, который принимает данные. Здесь интерфейсом может быть внешняя ссылка, например сетевое соединение или файл, или что-то внутреннее, например соглашение о вызове функций в служебной библиотеке.
Для выбранного интерфейса вставляются нечеткие данные, чтобы увидеть, как интерфейс обрабатывает эти недопустимые входные данные.
Моделирование угроз и набросок диаграммы потока данных могут помочь нам обнаружить потенциальный интерфейс.
За каждым интерфейсом может стоять множество уровней программного обеспечения. Крайне важно определить, на какой уровень программного обеспечения мы нацеливаемся для создания входных данных, которые могут пройти все проверки на предыдущих уровнях.
Давайте возьмем пример: HTTP-сервер принимает подписанный BLOB (большой двоичный объект). Объект) данных. В этом большом двоичном объекте у нас есть строка JSON, содержащая значения, используемые нашим приложением.
В этом примере у нас есть четыре потенциальных слоя для фаззинга:
1. HTTP-сообщения для сервера
2. Проверка подписи для нашего большого двоичного объекта данных
3. Анализ строки JSON
4. Наш код обрабатывает фактические значения.
В этом примере мы не нацелены на наши библиотеки HTTP, подписи и JSON.
Мы фаззинг нашего кода для генерации значений, упаковки значений в строку JSON, подпишите большой двоичный объект, создайте HTTP-сообщение и отправьте его в целевую реализацию.
Если у нас нет подходящего пакета автоматизации, нам придется создавать эти кейсы и внедрять в них фаззы, а это может занять значительное количество времени. Здесь нам не следует фаззить весь стек, это может привести к постоянным накладным расходам и может привести к поломке при изменении некоторых слоев.
Основное внимание уделяется пропускной способности тестовых примеров, а также следует учитывать функциональные возможности целевой программы, которые можно отключить или обойти, чтобы уменьшить накладные расходы и увеличить покрытие, достигаемое фаззером.
Рассматривая наш пример, нам нужно создать программу, которая напрямую передает значения в наш код обработки, минуя сетевое сообщение, пару хэш-вычислений, криптографическую проверку, преобразование в строку JSON и анализ JSON.
Мы должны убедиться, что эти изменения не скрывают и не создают новых ошибок, поскольку при реализации оптимизации фаззинга поведение целевой системы может измениться.
Эффективный способ начать фаззинг – это выдать случайные данные в любой интерфейс, который мы можем найти, вместо того, чтобы вводить тысячи тестовых случаев в секунду в оптимизированную среду фаззинга.
Примеры фаззеров< /h2>
Фаззеры на основе мутаций:
Этот тип фаззера создать проще всего, так как он изменяет существующие выборки данных для создания новых тестовых данных. Он подпадает под тупой фаззинг, но его можно использовать с более умными фаззерами. Мы можем сделать это, проведя некоторый уровень анализа образцов, чтобы гарантировать, что он изменяет только определенные части или не нарушает общую структуру ввода.
Фаззеры на основе генерации:
Этот тип фаззера требует большего интеллекта для создания тестовых данных с нуля, т. е. новые тестовые данные создаются на основе входной модели. Обычно он разбивает протокол или формат файла на фрагменты, которые затем выстраиваются в допустимый порядок, и эти фрагменты произвольно фаззингуются независимо
< strong>Фаззеры на основе протокола:
Это эффективный метод, основанный на знании формата протокола, который разрабатывает и подготавливает новые тестовые данные. Обычно это включает в себя запись спецификации в виде массива в инструмент, а затем на основе спецификации добавление искажений или недостатков во входных данных, шаблоне, серии и т. д.
Типы ошибок, обнаруженных с помощью нечеткого тестирования
Фазз-тестирование традиционно предназначено для проверки ошибок, вызывающих повреждение памяти. Сегодня в современных приложениях мы уделяем больше внимания не только ошибкам безопасности. Вот некоторые типы ошибок, которые можно обнаружить, сочетая фаззинг с другими типами тестирования:
Повреждение памяти и безопасность ошибки:
Критические ошибки безопасности, такие как переполнение буфера в куче, переполнение буфера в стеке, использование after free вместе с неинициализированными переменными и переполнение целых чисел.
Ошибки планирования:
Такие ошибки, как Race Condition, Hang, Livelock, можно обнаружить благодаря нечеткому тестированию.
Утверждения:
Некоторые ошибки утверждений. можно найти в рабочей среде (веб-браузер), обычно их можно найти в отладочной сборке.
Ошибки производительности:< /h3>
Длительное использование ОС без перезагрузки может повлиять на дисковую операционную систему ОС, что приведет к утечкам памяти.
Web и ошибки безопасности мобильного графического интерфейса:
Он также может выявить такие ошибки, как межсайтовый скриптинг (XSS), внедрение SQL, внедрение XPATH, внедрение кода PHP и внедрение команд оболочки.
Преимущества нечеткого тестирования
- Повышает безопасность приложения
- Это помогает в выявление критических нарушений безопасности, включая утечку памяти, необработанное исключение и т. д.
- Нечеткое тестирование помогает нам убедиться в надежности и безопасности нашего приложения.
- Нечеткое тестирование выявляет серьезные уязвимости в приложении, которые могут быть легко использованы хакерами.
- Оно помогает выявить проблемы, которые полностью упускаются из виду командой тестирования.
- Это дает нам четкое представление об общей надежности программного приложения.
- Нечеткое тестирование может обнаружить даже логические ошибки, если оно реализовано на уровне приложения.
Недостатки нечеткого тестирования
- Оно не выявляет угрозы безопасности, которые не вызывают сбоев программы, например, некоторые вирусы, черви, трояны и т. д.
- Это очень сложно для установки граничных условий со случайными входными данными.
- Нечеткое тестирование требует значительного количества времени для правильного выполнения; оно не будет эффективным, если у вас меньше времени.
- Обычно оно выявляет очень простые ошибки, которые можно легко найти. путем тестирования на проникновение.
- Интерпретировать данные нечеткого тестирования может быть сложно.
- Для его эффективной реализации требуется время, усилия и труд.
- Сложно проанализировать сценарий краш-теста, и он не дает нам много знаний о том, как программное обеспечение работает внутри
Инструменты нечеткого тестирования
Открытый исходный код
Мутационные фаззеры:
- Американский нечеткий lop
- Радамса – стая дураков
- APIFuzzer – фазз-тест без написания кода
- Jazzer – фаззинг для JVM
Fuzzing Frameworks
- Sulley Fuzzing Framework
- Boofuzz
- BFuzz
Фаззеры для конкретных доменов
- Microsoft SDL MiniFuzz File Fuzzer
- Microsoft SDL Regex Fuzzer
- ABNF Fuzzer
Коммерческие продукты
- Пакет продуктов Codenomicon
- Peach Fuzzing Platform
- Spirent Avalanche NEXT
- Продукт beSTORM от Beyond Security
- Продукт ForAllSecure Mayhem
- CI Fuz
Заключение
Короче говоря, нечеткое тестирование можно проводить путем вставки в программу неверных, неожиданных, иногда случайных входных данных в надежде вызвать новые или непредвиденные пути кода и ошибки. Фаззинг — старый метод, но он широко используется, поскольку это очень эффективный метод поиска ошибок. Чтобы получить максимальные результаты, фазз-тестирование необходимо интегрировать в наш процесс разработки.
TAG: qa
Еще об этом:
 ТОП 150+ ВОПРОСОВ И ОТВЕТОВ НА ИНТЕРВЬЮ ПО ТЕСТИРОВАНИЮ ПРОГРАММНОГО ОБЕСПЕЧЕНИЯ
ТОП 150+ ВОПРОСОВ И ОТВЕТОВ НА ИНТЕРВЬЮ ПО ТЕСТИРОВАНИЮ ПРОГРАММНОГО ОБЕСПЕЧЕНИЯ
 150+ ЛУЧШИХ ВОПРОСОВ И ОТВЕТОВ НА ИНТЕРВЬЮ О ТЕСТИРОВАНИИ ПРОГРАММНОГО ОБЕСПЕЧЕНИЯ
150+ ЛУЧШИХ ВОПРОСОВ И ОТВЕТОВ НА ИНТЕРВЬЮ О ТЕСТИРОВАНИИ ПРОГРАММНОГО ОБЕСПЕЧЕНИЯ
 ЛУЧШИЕ ИНСТРУМЕНТЫ ТЕСТИРОВАНИЯ ВЕБ-ПРИЛОЖЕНИЙ (БЕСПЛАТНЫЕ И ПЛАТНЫЕ) НА 2022 ГОД
ЛУЧШИЕ ИНСТРУМЕНТЫ ТЕСТИРОВАНИЯ ВЕБ-ПРИЛОЖЕНИЙ (БЕСПЛАТНЫЕ И ПЛАТНЫЕ) НА 2022 ГОД
 100+ ВИДОВ ТЕСТИРОВАНИЯ ПРОГРАММНОГО ОБЕСПЕЧЕНИЯ – ПОЛНЫЙ СПИСОК
100+ ВИДОВ ТЕСТИРОВАНИЯ ПРОГРАММНОГО ОБЕСПЕЧЕНИЯ – ПОЛНЫЙ СПИСОК
 РУКОВОДСТВО ПО FUZZ-ТЕСТИРОВАНИЮ | ТО, ЧТО ВЫ ДОЛЖНЫ ЗНАТЬ
РУКОВОДСТВО ПО FUZZ-ТЕСТИРОВАНИЮ | ТО, ЧТО ВЫ ДОЛЖНЫ ЗНАТЬ
 ЛУЧШЕЕ ПРОГРАММНОЕ ОБЕСПЕЧЕНИЕ ДЛЯ ДИНАМИЧЕСКОГО ТЕСТИРОВАНИЯ БЕЗОПАСНОСТИ ПРИЛОЖЕНИЙ (DAST) В 2022 ГОДУ
ЛУЧШЕЕ ПРОГРАММНОЕ ОБЕСПЕЧЕНИЕ ДЛЯ ДИНАМИЧЕСКОГО ТЕСТИРОВАНИЯ БЕЗОПАСНОСТИ ПРИЛОЖЕНИЙ (DAST) В 2022 ГОДУ
 ЛУЧШЕЕ ПРОГРАММНОЕ ОБЕСПЕЧЕНИЕ ДЛЯ ПРЕДОТВРАЩЕНИЯ ПОТЕРИ ДАННЫХ (БЕСПЛАТНОЕ И ПЛАТНОЕ) НА 2022 ГОД
ЛУЧШЕЕ ПРОГРАММНОЕ ОБЕСПЕЧЕНИЕ ДЛЯ ПРЕДОТВРАЩЕНИЯ ПОТЕРИ ДАННЫХ (БЕСПЛАТНОЕ И ПЛАТНОЕ) НА 2022 ГОД
 ЛУЧШИЕ ИНСТРУМЕНТЫ ТЕСТИРОВАНИЯ МОБИЛЬНЫХ ПРИЛОЖЕНИЙ В 2024 ГОДУ ДЛЯ ANDROID И IOS
ЛУЧШИЕ ИНСТРУМЕНТЫ ТЕСТИРОВАНИЯ МОБИЛЬНЫХ ПРИЛОЖЕНИЙ В 2024 ГОДУ ДЛЯ ANDROID И IOS
 11 ЛУЧШИХ ПРОГРАММ ДЛЯ ПРЕДОТВРАЩЕНИЯ ПОТЕРИ ДАННЫХ (БЕСПЛАТНО И ПЛАТНО) НА 2023 ГОД
11 ЛУЧШИХ ПРОГРАММ ДЛЯ ПРЕДОТВРАЩЕНИЯ ПОТЕРИ ДАННЫХ (БЕСПЛАТНО И ПЛАТНО) НА 2023 ГОД
 ЛУЧШИЕ СРЕДСТВА СКАНИРОВАНИЯ ОЦЕНКИ УЯЗВИМОСТЕЙ (БЕСПЛАТНЫЕ И ПЛАТНЫЕ) НА 2022 ГОД
ЛУЧШИЕ СРЕДСТВА СКАНИРОВАНИЯ ОЦЕНКИ УЯЗВИМОСТЕЙ (БЕСПЛАТНЫЕ И ПЛАТНЫЕ) НА 2022 ГОД

