В предыдущих статьях руководства по Selenium Python мы рассмотрели «Обработку файлов cookie в Selenium Python». В этом уроке мы научимся Работе с Excel в Selenium Python.
Мы можем работать с книгой Excel в Selenium WebDriver. Excel, также называемый электронной таблицей, может иметь такие расширения, как .xlsx, .xlsm и т. д. Excel состоит из нескольких листов.
Каждый рабочий лист разделен на строки и столбцы, имеющие адрес. Адрес строк начинается с 1, а адрес столбца — с A. Ячейка внутри листа — это точка пересечения строки и столбца.
Каждая ячейка на листе имеет уникальный адрес, определяемый сочетание адреса строки и столбца. Из нескольких листов в книге тот, над которым мы сейчас работаем, называется активным.
При работе с инструментом Selenium вместе с языком Python мы используем библиотеку OpenPyXL для доступа к Excel из версии 2010. Python не предоставляет эту библиотеку автоматически.
Нам нужно запустить команду pip install openpyxl , чтобы получить библиотеку OpenPyXL. Также нам нужно добавить в наш код оператор import openpyxl, чтобы получить все методы этой библиотеки.
Чтобы получить активный лист в книге, нам нужно использовать < Strong>load_workbook (), который принимает путь к Excel в качестве параметра, а затем использует метод active.
Реализация кода для идентификации активного рабочего листа.
import openpyxl # для загрузки книги по ее пути bk = openpyxl.load_workbook(“C:\STM\Python.xlsx”) # для идентификации активного рабочего листа s = bk.active
Чтобы прочитать значение конкретной ячейки , нам нужно выполнить все вышеперечисленные шаги. Затем нам нужно применить метод cell () к активному объекту рабочего листа. Этот метод содержит номер строки и столбца в качестве параметров. Наконец, мы будем использовать метод value для фактического чтения данных ячейки.
Реализация кода для чтения значения ячейки.
import openpyxl # для загрузки книги по ее пути bk = openpyxl.load_workbook(“C:\STM\Python.xlsx”) # для идентификации активного рабочего листа s = bk.active # для идентификации ячейки c = s.cell ( row = 3, columns = 1) # для получения значения ячейки и печати print ( c.value)
Чтобы записать значение в определенную ячейку, нам нужно идентифицировать активный рабочий лист. Затем нам нужно применить метод cell () к активному объекту рабочего листа. Этот метод содержит номер строки и столбца в качестве параметров.
Далее, чтобы установить значение, нам нужно использовать метод value. Наконец, чтобы сохранить книгу, нам нужно применить метод save () к объекту книги. Метод save() принимает в качестве параметра путь к файлу, который необходимо сохранить.
Реализация кода для записи значения ячейки.import openpyxl # для загрузки книги по ее пути bk = openpyxl.load_workbook(“C:\STM\Python.xlsx”) # для идентификации активного рабочего листа s = bk.active # для идентификации ячейка c = s.cell (row = 2, columns = 8) # для записи значения в эту ячейку s.cell (row = 2, columns = 8).value = "Python" # чтобы сохранить книгу в папке bk.save ("C:\STM\Python.xlsx")
Чтобы получить максимальное количество строк и столбцов на листе, нам нужно определить активный рабочий лист. Затем нам нужно применить метод max_row к активному объекту рабочего листа, чтобы получить общее количество занятых строк. Кроме того, нам нужно применить метод max_column к активному объекту рабочего листа, чтобы получить общее количество занятых столбцов.
Реализация кода для определения максимального количества занятых строк и столбцов.import openpyxl # для загрузки книги по ее пути bk = openpyxl.load_workbook(“C:\STM\Python.xlsx”) # для идентификации активного рабочего листа s = bk.active # для определения максимального количества строк print ( s.max_row) # для определения максимального количества столбцов print ( s.max_column)
Чтобы получить все данные ячеек на листе, нам нужно идентифицировать активный лист. Затем нам нужно применить max_rowметод для активного объекта рабочего листа, чтобы получить общее количество занятых строк. Кроме того, нам необходимо применить метод max_column к активному объекту рабочего листа, чтобы получить общее количество занятых столбцов.
Чтобы получить данные ячейки, мы затем переберем максимальное количество строк и столбцов. которые заняты на листе, а затем извлекают значение ячейки.
Реализация кода для получения всех значений ячеек на листе.
import openpyxl # для загрузки книги по ее пути bk = openpyxl.load_workbook(“C:\STM\Python.xlsx”) # для идентификации активного рабочего листа s = bk.active # для определения максимального количества строк print ( s.max_row ) # итерируем до подсчета занятых строк для m в диапазоне ( 1, s.max_row + 1): # итерируем до подсчета занятых столбцов для n в диапазоне ( 1, s.max_column + 1): # чтобы получить ячейку data и распечатать print (s.cell (row=m, columns=n). value)
Чтобы получить все данные ячеек определенной строки на листе, нам нужно идентифицировать активный лист. Затем нам нужно применить max_rowметод для активного объекта рабочего листа, чтобы получить общее количество занятых строк. Кроме того, нам нужно применить метод max_column к активному объекту рабочего листа, чтобы получить общее количество занятых столбцов.
Чтобы получить данные ячейки, мы затем переберем максимальное количество строк и столбцов, занятых на листе, а затем получим значение ячейки. Как только мы получим значение ячейки, мы выполним условный оператор и получим все значения из определенной строки, которая соответствует нашему требованию.

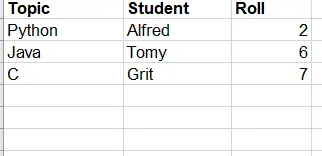
Давайте рассмотрим книгу, имеющую лист с приведенным выше набором данных. Предположим, мы хотим получить сведения о студенте по теме Python.
Реализация кода для приведенного выше сценария.import openpyxl # для загрузки книги по ее пути bk = openpyxl.load_workbook(“C:\STM Python.xlsx”) # для определения активного рабочего листа s = bk.active # для определения максимального количества строк print ( s.max_row) # итерация до достижения количества занятых строк для m в диапазоне ( 1, s.max_row + 1): # чтобы получить все значения ячеек из столбца 1, если s.cell (row=m, columns=1).value == "Python" : # итерация до подсчета количества занятых столбцов для n в диапазоне ( 1, s.max_column + 1): # чтобы получить все данные ячейки из строки и напечатать print (s.cell (row=m, columns=n). value)
В следующей статье мы узнаем более 100 вопросов на собеседовании по Selenium.
TAG: qa
Еще об этом:
 РАБОТА С EXCEL В SELENIUM PYTHON
РАБОТА С EXCEL В SELENIUM PYTHON
 КАК ОБРАЩАТЬСЯ С ВЕБ-ТАБЛИЦАМИ В SELENIUM PYTHON
КАК ОБРАЩАТЬСЯ С ВЕБ-ТАБЛИЦАМИ В SELENIUM PYTHON
 ВОПРОСЫ НА ИНТЕРВЬЮ ПО ПИТОНУ
ВОПРОСЫ НА ИНТЕРВЬЮ ПО ПИТОНУ
 РУКОВОДСТВО ПО SELENIUM PYTHON ДЛЯ НАЧИНАЮЩИХ
РУКОВОДСТВО ПО SELENIUM PYTHON ДЛЯ НАЧИНАЮЩИХ
 ТОП 40+ ВОПРОСОВ И ОТВЕТОВ НА ИНТЕРВЬЮ ПО JAVA В 2022 Г.
ТОП 40+ ВОПРОСОВ И ОТВЕТОВ НА ИНТЕРВЬЮ ПО JAVA В 2022 Г.
 100 САМЫХ ПОПУЛЯРНЫХ ПРОДВИНУТЫХ ВОПРОСОВ И ОТВЕТОВ НА ИНТЕРВЬЮ ПО SELENIUM
100 САМЫХ ПОПУЛЯРНЫХ ПРОДВИНУТЫХ ВОПРОСОВ И ОТВЕТОВ НА ИНТЕРВЬЮ ПО SELENIUM
 ПИТОННЫЕ СТРУНЫ
ПИТОННЫЕ СТРУНЫ
 Selenium with Python Tutorial
Selenium with Python Tutorial
 МНОГОСТРОЧНАЯ СТРОКА ПИТОНА
100+ САМЫХ ПОПУЛЯРНЫХ ВОПРОСОВ И ОТВЕТОВ НА ИНТЕРВЬЮ по SQL
МНОГОСТРОЧНАЯ СТРОКА ПИТОНА
100+ САМЫХ ПОПУЛЯРНЫХ ВОПРОСОВ И ОТВЕТОВ НА ИНТЕРВЬЮ по SQL

