Для автоматизированного тестирования важно иметь возможность идентифицировать веб-элементы тестируемого приложения (AUT). Чтобы научиться находить веб-элементы вручную, может потребоваться много времени и опыта. Здесь мы покажем вам, как легко и вручную находить веб-элементы с помощью XPath в Selenium.+
Одной из полезных функций Selenium являются локаторы. Локаторы позволяют нам находить веб-элементы. Если веб-элементы не найдены с помощью локаторов, таких как идентификатор, имя класса, имя, текст ссылки и т. д., мы используем XPath для поиска веб-элементов на веб-странице.
Прежде чем научиться писать динамический XPath в автоматизации Selenium, мы узнаем, что такое локатор XPath в Selenium и следующее
Что такое XPath в Selenium?
< р>XPath предназначен для навигации по XML-документам с целью выбора отдельных элементов, атрибутов или какой-либо другой части XML-документа для конкретной обработки. XPath создает надежные локаторы, но с точки зрения производительности он медленнее (особенно в старых версиях IE) по сравнению с CSS Selector.
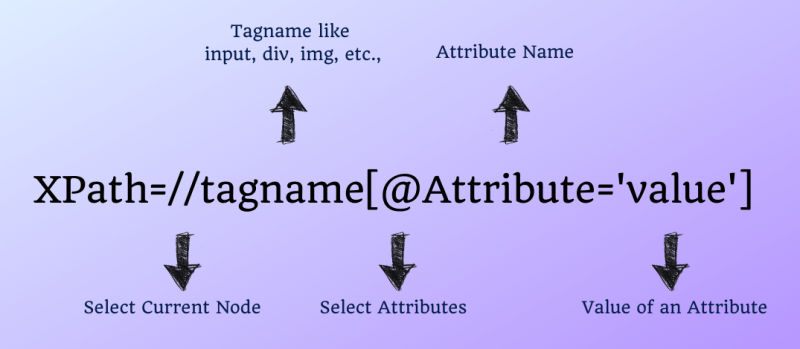
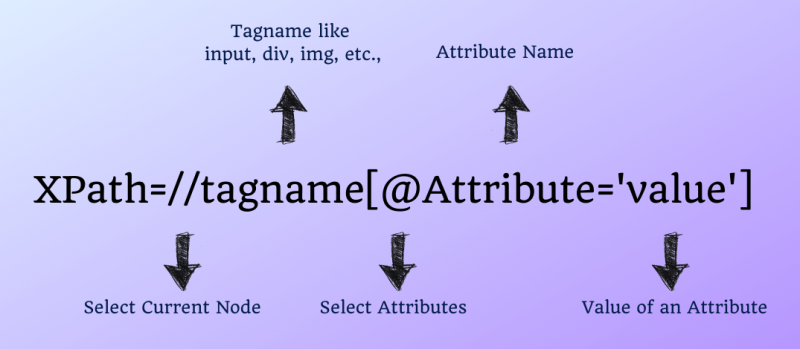
Синтаксис для XPath Selenium:
| 1 | Xpath=//tagname[@Attribute='value'] |
- // — выберите текущий узел.
- Имя тега — Имя тега соответствующего узла.
- @– Выберите атрибут.
- Атрибут – Имя атрибута узла.
- Значение – Значение атрибута.
Синтаксис :
| 1 | findElement(By.xpath(“XPath”)); |
Не пропустите Расширения Chrome для поиска XPath
Какие существуют типы XPath?
В Selenium существует два типа XPath
- Абсолютный XPath
- Относительный XPath
< blockquote class=wp-block-quote>
Примечание. Интервьюеры могут спросить вас, в чем разница между абсолютным XPath и относительным XPath.
#1. Абсолютный XPath
Абсолютный XPath начинается с корневого узла и заканчивается узлом требуемого элемента-потомка. Он начинается с верхнего узла HTML и заканчивается входным узлом. Он начинается с одной косой черты (/), как показано ниже.
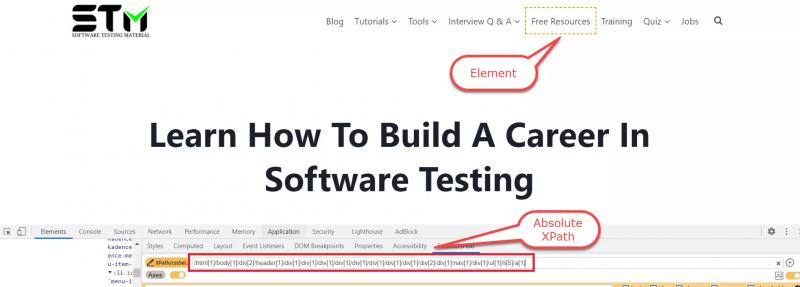
Пример абсолютного XPath
| 1 | /html[1]/body[1]/div[2]/header[1]/div[1]/div[1]/div[1]/div[1]/div[1]/div[1] /div[1]/div[1]/div[2]/div[1]/nav[1]/div[1]/ul[1]/li[5]/a[1] |
< p>Еще один пример
| 1 | /html/body/div/div/form/table/tbody/tr/td/input |
#2. Относительный XPath
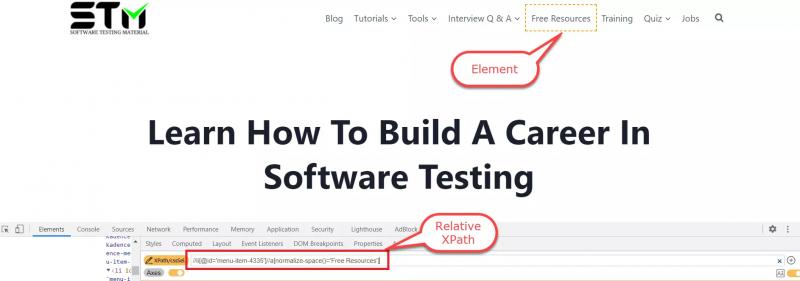
Относительный XPathначинается с любого узла между HTML-страницей и узлом текущего элемента (последним узлом элемента). Он начинается с двойной косой черты (//), как показано ниже.
Пример относительного XPath
< table class=crayon-table>
Еще один пример
| 1 | //input@id='email'] |
Что такое динамический XPath в Selenium и как найти XPath?
< p>Иногда мы не можем идентифицировать элемент с помощью локаторов, таких как идентификатор, класс, имя и т. д. В таких случаях мы используем XPath для поиска элемента на веб-странице.
В иногда XPath может динамически меняться, и нам нужно обрабатывать элементы при написании скриптов.
Стандартный способ написания XPath может не работать, и нам нужно писать динамический XPath в скриптах selenium.
Что такое оси XPath?
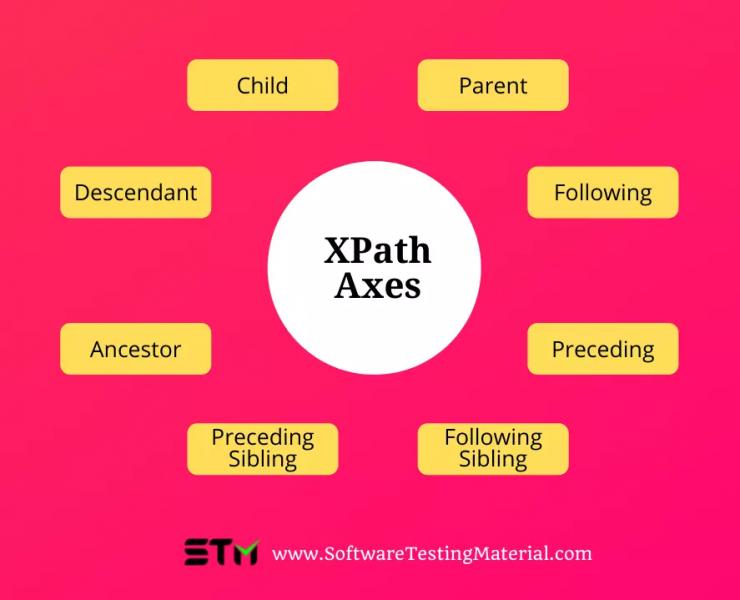
Оси XPath ищут разные узлы в XML-документе из контекстного (текущего) узла. Он используется для поиска узла, который относится к узлу в этом дереве.
Оси XPath — это методы, используемые для поиска динамических элементов, которые в противном случае были бы невозможны при использовании стандартных методов XPath, которые не включают идентификатор, имя класса, имя или другие идентификаторы.
Методы осей используются для поиска тех элементов, которые динамически изменяются. при обновлении или любых других операциях. В Selenium Webdriver обычно используется несколько методов осей, таких как дочерний, родительский, предковый, одноуровневый, предыдущий, самостоятельный и т. д.
Одной из сложных и трудоемких задач автоматизации тестирования является модификация тестовых сценариев при изменении AUT, особенно на ранних этапах разработки программного обеспечения. Разработчики могут довольно часто менять идентификаторы и элементы от одной сборки к другой. Кроме того, во время выполнения элементы AUT могут динамически изменяться.
Чтобы справиться с этими проблемами, тестировщики автоматизации не должны устанавливать фиксированные XPath для элементов в тестовых примерах, а вместо этого динамически создавать сценарии XPath на основе определенных шаблонов. .
| Имя оси | Описание |
|---|---|
| ancestor | Показывает всех предков (родительских, прародительских и т. д.), связанных с контекстным (текущим) узлом. |
| предок-или-я | Показывает контекстный (текущий) узел и всех предков. |
| attribute | Показывает все атрибуты контекстного (текущего) узла. |
| ребенок | Показывает всех дочерних элементов контекстного (текущего) узла. |
| потомок | Указывает всех потомков (дочерних, внуков и т. д.). ) контекстного (текущего) узла. |
| потомок-или-я | Указывает всех потомков (дочерних элементов, внуков и т. д.). .) контекстного (текущего) узла и самого текущего узла. |
| following | Указывает все узлы, которые появляются после контекстного (текущего) узла. |
| following-sibling | Указывает все одноуровневые узлы после контекста (текущий) узел. |
| namespace | Указывает все узлы пространства имен контекстного (текущего) узла. |
| parent | Указывает родителя контекстного (текущего) узла. |
| предыдущий | Указывает все узлы, которые появляются перед контекстным (текущим) узлом в структуре HTML DOM. Это не указывает предка, атрибут и пространство имен. контекстный (текущий) узел в структуре HTML DOM. Здесь не указываются потомок, атрибут и пространство имен. |
| self | Указывает контекстный (текущий) узел. |
Различные способы написания Dynamic XPath в Selenium с примерами
Давайте рассмотрим различные способы написания динамического XPath в Selenium на примерах:
- Использование одиночной косой черты
- Использование двойной косой черты
- Использование одного атрибута
- Использование нескольких атрибутов
- Использование И
- Использование ИЛИ
- Использование contains()
- Использование start-with()
- Использование text()
- Использование last()
- Использование position()
- Использование index
- Использование следующих осей XPath
- Использование предыдущих осей XPath
Узнайте, как написать динамический селектор CSS в Selenium WebDriver [без каких-либо инструментов]
Вот обучающее видео «Создание динамического XPath в Selenium WebDriver»:
Если вам понравилось это видео, подпишитесь на наш канал YouTube для получения дополнительных видеоуроков.
Здесь я пытаюсь найти элемент (поле “Электронная почта или телефон”) на странице входа в Gmail

HTML-код: (страница входа в Gmail – поле электронной почты)
| 12 | <input id=”Электронная почта” type=”email” value=”” Проверка орфографии=”false” class=”emailClass”autofocus=”” name=”Электронная почта” placeholder=”Введите адрес электронной почты”/> |
#1. Использование одиночной косой черты
Этот механизм также известен как поиск элементов с использованием Абсолютного XPath.
Одиночная косая черта используется для создания XPath с абсолютным путем, т. е. XPath быть создан, чтобы начать выбор с узла документа/начального узла/родительского узла.
Синтаксис:
| 1 | html/body/div[1]/div[2]/div[2]/div[1]/form/div[1]/div/div[1] /div/div/input[1] |
#2. Использование двойной косой черты
Этот механизм также известен как поиск элементов с использованием относительного XPath.
Двойная косая черта используется для создания XPath с относительным путем, т. е. XPath создается для начала выделения из любого места в документе. – Поиск предыдущей строки по всей странице (DOM)
Синтаксис:
| 1 | //form/div[1]/div/div[1]/div/div/input[1] |
#3. Использование одного атрибута
Вы можете написать синтаксис двумя способами, как указано ниже. Включая или исключая тег HTML. Если вы хотите исключить тег HTML, вам нужно использовать *
Синтаксис:
| 12345 | //<HTML-тег>[@attribute_name='attribute_value'] или //*[@attribute_name='attribute_value'] |
Примечание: '*' после двойной косой черты соответствует любому тегу с нужным text
XPath основан на приведенном выше HTML:
| 12345 | //input[@id='Email'] или //*[@id='Email'] |
< h3 id=h-4-using-multiple-attribute>#4. Использование нескольких атрибутов
Синтаксис:
| 12345 | //<HTML-тег>[@attribute_name1='attribute_value1'][@attribute_name2='attribute_value2] или //*[@attribute_name1='attribute_value1'][@attribute_name2='attribute_value2] |
XPath на основе приведенного выше HTML:
| 12345 | //input[@id='Электронная почта'][@name='Электронная почта'] или //*[@id='Электронная почта'][@name='Электронная почта'] |
#5. Использование И
Синтаксис:
| 12345 | //<HTML-тег>[@attribute_name1='attribute_value1' и @attribute_name2='attribute_value2] или //*[@attribute_name1='attribute_value1' и @attribute_name2='attribute_value2] |
XPath на основе приведенного выше HTML:
| 12345 | //input[@id='Электронная почта' и @name='Электронная почта'] или //*[@id='Электронная почта' и @name='Электронная почта'] |
< h3 id=h-6-using-or>#6. Использование ИЛИ
Синтаксис:
| 12345 | //<HTML-тег>[@attribute_name1='attribute_value1' или @attribute_name2='attribute_value2] или //*[@attribute_name1='attribute_value1' или @attribute_name2='attribute_value2] |
XPath на основе приведенного выше HTML:
| 12345 | //input[@id='Электронная почта' или @name='Электронная почта'] или //*[@id='Электронная почта' или @name='Электронная почта'] |
< h3 id=h-7-using-contains>#7. Использование contains()
Содержит() – это метод, используемый для идентификации элемента, который изменяется динамически и когда мы знакомы с некоторой частью значения атрибута этого элемента.
Синтаксис:
| 12345 | //<HTML-тег>[содержит(@attribute_name,'attribute_value')] или //*[содержит(@attribute_name,'attribute_value')] |
< strong>XPath на основе приведенного выше HTML:
| 12345678910111213 | //input[contains(@id,'Email')] или //*[contains(@id,' Email')] или //input[contains(@name,'Email')] или //*input[contains(@name,'Email')] |
#<сильный>8. Использование start-with()
Метод starts-with() используется для идентификации элемента, когда мы знакомы со значением атрибута (начиная с указанного текста) элемента.
Синтаксис:< textarea wrap=soft class="crayon-plain print-no" data-settings=dblclick только для чтения стиль=-moz-tab-size:4;-o-tab-size:4;-webkit-tab-size:4;tab -size:4;font-size:12px!important;line-height:15px!important>//<HTML-тег>[starts-with(@attribute_name,'attribute_value')] или //* [начинается с(@attribute_name,'attribute_value')]
| 12345 | //<HTML-тег>[начинается с(@attribute_name,'attribute_value')] или //*[начинается с (@attribute_name,'attribute_value')] |
XPath на основе приведенного выше HTML:<класс таблицы =crayon-table>
#9. Использование text()
Этот механизм используется для поиска элемента на основе текста, доступного на веб-странице
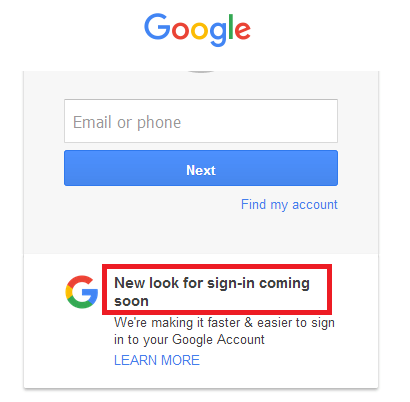
Как указано выше изображение, мы могли бы идентифицировать текст элементов на основе приведенного ниже xpath. -size:4;-webkit-tab-size:4;tab-size:4;font-size:12px!important;line-height:15px!important>//*[text()='Новый внешний вид для входа скоро']
| 1 | //*[text()='Скоро появится новый вид входа'] |
#10. Использование last()
Выбирает последний элемент (указанного типа) из всех присутствующих элементов ввода

Чтобы определить элемент (последнее текстовое поле) «Ваш текущий адрес электронной почты», мы могли бы использовать приведенный ниже xpath.
| 1 | findElement(By.xpath(“(//input[@type='text'])[ last()]”)) |
Чтобы идентифицировать элемент «Год», мы могли бы использовать приведенный ниже путь xpath.
[last()-1] – выбирает предпоследний элемент (указанного типа) из всех присутствующих элементов ввода
| 1 | findElement(By.xpath(“(//input[@type='text'])[last()-1]”)) |
#11. Использование position()
Выбирает элемент из всех присутствующих элементов ввода в зависимости от предоставленного номера позиции
В приведенном ниже xpath [@type='text'] найдет текстовое поле а функция [position()=2] найдет текстовое поле, расположенное на 2 позиции сверху.
| 12345 | findElement(By.xpath(“(//input[@type='text'])[position()=2]”)) или findElement(By.xpath(“(//input[@type='text'] )[2]”)) |
#12. Использование индекса
Указав положение индекса в квадратных скобках, мы могли бы перейти к n-му элементу. Основываясь на приведенном ниже xpath, мы можем определить поле «Фамилия». -size:4;-webkit-tab-size:4;tab-size:4;font-size:12px!important;line-height:15px!important>findElement(By.xpath("//label[ 2]"))
| 1 | findElement(By.xpath(“//label[2]”)) |
#13. Использование следующих осей XPath
Используя это, мы могли бы выбрать все на веб-странице после закрывающего тега текущего узла
xpath поля FirstName выглядит следующим образом: webkit-tab-size:4;tab-size:4;font-size:12px!important;line-height:15px!important>//*[@id='FirstName']
| 1 | //*[@id='FirstName ']
Чтобы определить поле ввода текста после поля FirstName, нам нужно использовать приведенный ниже xpath.
Здесь я использовал следуя осям xpath и два двоеточия, а затем указал требуемый тег (т. е. ввод) Чтобы идентифицировать только поле ввода после поля FirstName, нам нужно использовать приведенный ниже xpath.
№ 14. Использование предшествующих осей XPathВыбирает все узлы, которые появляются перед текущим узлом в документе, за исключением предков, узлов атрибутов и узлов пространства имен xpath поля LastName выглядит следующим образом
Для идентификации поле ввода типа text перед полем LastName, нам нужно использовать приведенный ниже xpath. ;-o-tab-size:4;-webkit-tab-size:4;tab-size:4;размер шрифта:12px!важно;высота строки:15px!важно>//*[@id=&# 39;LastName']//preceding::input[@type='text']"
Здесь я использовал предшествующие оси xpath и два двоеточия, а затем указал требуемый тег (т. е. ввод). ЗаключениеXPath в Selenium используется для поиска элементов, когда другие локаторы этого не делают. Два типа Selenium XPath:
Различные способы поиска элементов на веб-странице с помощью Selenium XPath обсуждаемое здесь, будет полезно, когда вы работаете над своим проектом в реальном времени. Если у вас есть какие-либо вопросы, прокомментируйте их ниже в разделе комментариев. Понравился этот пост? Не забудьте поделиться им! Вот несколько тщательно отобранные статьи, которые вы можете прочитать дальше: Руководство по Selenium Еще об этом: 100 САМЫХ ПОПУЛЯРНЫХ ПРОДВИНУТЫХ ВОПРОСОВ И ОТВЕТОВ НА ИНТЕРВЬЮ ПО SELENIUM 100 САМЫХ ПОПУЛЯРНЫХ ПРОДВИНУТЫХ ВОПРОСОВ И ОТВЕТОВ НА ИНТЕРВЬЮ ПО SELENIUM
 ИЗУЧИТЕ РУКОВОДСТВО ПО СЕЛЕКТОРУ CSS В SELENIUM WEBDRIVER [БЕЗ ИСПОЛЬЗОВАНИЯ КАКИХ-ЛИБО ИНСТРУМЕНТОВ] ИЗУЧИТЕ РУКОВОДСТВО ПО СЕЛЕКТОРУ CSS В SELENIUM WEBDRIVER [БЕЗ ИСПОЛЬЗОВАНИЯ КАКИХ-ЛИБО ИНСТРУМЕНТОВ]
 СТРУКТУРА, УПРАВЛЯЕМАЯ ДАННЫМИ, В SELENIUM WEBDRIVER | МАТЕРИАЛ ДЛЯ ТЕСТИРОВАНИЯ ПРОГРАММНОГО ОБЕСПЕЧЕНИЯ СТРУКТУРА, УПРАВЛЯЕМАЯ ДАННЫМИ, В SELENIUM WEBDRIVER | МАТЕРИАЛ ДЛЯ ТЕСТИРОВАНИЯ ПРОГРАММНОГО ОБЕСПЕЧЕНИЯ
 VBSCRIPT ДЛЯ АВТОМАТИЗАЦИИ (QTP/UFT) ТЕСТИРОВАНИЯ – ЧАСТЬ 5 VBSCRIPT ДЛЯ АВТОМАТИЗАЦИИ (QTP/UFT) ТЕСТИРОВАНИЯ – ЧАСТЬ 5
 VBSCRIPT ДЛЯ АВТОМАТИЗАЦИИ (QTP/UFT) ТЕСТИРОВАНИЯ – ЧАСТЬ 4 VBSCRIPT ДЛЯ АВТОМАТИЗАЦИИ (QTP/UFT) ТЕСТИРОВАНИЯ – ЧАСТЬ 4
 100+ САМЫХ ПОПУЛЯРНЫХ ВОПРОСОВ И ОТВЕТОВ НА ИНТЕРВЬЮ по SQL 100+ САМЫХ ПОПУЛЯРНЫХ ВОПРОСОВ И ОТВЕТОВ НА ИНТЕРВЬЮ по SQL
 НАЙТИ XPATH – 10 ЛУЧШИХ РАСШИРЕНИЙ ДЛЯ CHROME
КАК ОБРАЩАТЬСЯ С ВЫПАДАЮЩИМ СПИСКОМ И МНОЖЕСТВЕННЫМ ВЫБОРОМ, ИСПОЛЬЗУЯ SELENIUM WEBDRIVER
What is an EMail?
JAVASCRIPTEXECUTOR В SELENIUM WEBDRIVER, МЕТОДЫ С ПРИМЕРАМИ НАЙТИ XPATH – 10 ЛУЧШИХ РАСШИРЕНИЙ ДЛЯ CHROME
КАК ОБРАЩАТЬСЯ С ВЫПАДАЮЩИМ СПИСКОМ И МНОЖЕСТВЕННЫМ ВЫБОРОМ, ИСПОЛЬЗУЯ SELENIUM WEBDRIVER
What is an EMail?
JAVASCRIPTEXECUTOR В SELENIUM WEBDRIVER, МЕТОДЫ С ПРИМЕРАМИ
Iconic One Theme | Powered by Wordpress

detector |
